Firmware-Update - 4.8 - Insider Preview 7 - jetzt verfügbar
• Nachkommastellen einstellbar für VISU Wetter-Widget.
• Logik-Editor: Umrechnungen (×/÷ 10, 100, 1.000, 1.000.000) per Klick.
• KNX: Unterstützung für neue Geräte‑Applikation.
• VISU: Wochentage im Wetter‑Widget aktualisieren nun automatisch über Nacht.
• MQTT/REST: Zusätzliche Zeichen in Selektoren für JSON
• Logik: Datentyp‑Konvertierungen, Anpassungen für Trigger-Datentypen, Hinweis bei externen Änderungen an Verknüpfungen und weitere Logiken zur Farbumwandlung
Mehr Infos im Wiki https://elabnet.atlassian.net/wiki/x/PIAD4
• Nachkommastellen einstellbar für VISU Wetter-Widget.
• Logik-Editor: Umrechnungen (×/÷ 10, 100, 1.000, 1.000.000) per Klick.
• KNX: Unterstützung für neue Geräte‑Applikation.
• VISU: Wochentage im Wetter‑Widget aktualisieren nun automatisch über Nacht.
• MQTT/REST: Zusätzliche Zeichen in Selektoren für JSON
• Logik: Datentyp‑Konvertierungen, Anpassungen für Trigger-Datentypen, Hinweis bei externen Änderungen an Verknüpfungen und weitere Logiken zur Farbumwandlung
Mehr Infos im Wiki https://elabnet.atlassian.net/wiki/x/PIAD4
[Beantwortet] [V4.5] TWS350Q, Login klappt nicht mehr, RUN-LED blinkt doppelt
Forumsregeln
- Denke bitte an aussagekräftige Titel und gebe dort auch die [Firmware] an. Wenn ETS oder CometVisu beteiligt sind, dann auch deren Version
- Bitte mache vollständige Angaben zu Deinem Server, dessen ID und dem Online-Status in Deiner Signatur. Hilfreich ist oft auch die Beschreibung der angeschlossener Hardware sowie die verwendeten Protokolle
- Beschreibe Dein Projekt und Dein Problem bitte vollständig. Achte bitte darauf, dass auf Screenshots die Statusleiste sichtbar ist
- Bitte sei stets freundlich und wohlwollend, bleibe beim Thema und unterschreibe mit deinem Vornamen. Bitte lese alle Regeln, die Du hier findest: https://wiki.timberwolf.io/Forenregeln
-
gbglace
- Beiträge: 4320
- Registriert: So Aug 12, 2018 10:20 am
- Hat sich bedankt: 1523 Mal
- Danksagung erhalten: 2069 Mal
Es gibt jetzt einige Lösungen aber eben nicht jeder hatte den Server gekauft, um da regelmäßig Details weiter zu beobachten. Gerade die 350-er waren ja auch eher die kleinsten an Ressourcenausstattung, Da hat man eh einen anderen Scope der Nutzung gehabt. Und das was der Server da mindestens können sollte, konnte er bis dahin schon. Insofern ein nachvollziehbares Nutzerverhalten, nur alle paar Monate mal auf die Oberfläche zu schauen und nicht jeden Thread mit ggf vergleichbaren Symptomen hier im Forum zu begleiten.
Grüße Göran
#1 Timberwolf 2600 Velvet Red TWS #225 / VPN aktiv / Reboot OK
#2 Timberwolf 2600 Organic Silver TWS #438 / VPN aktiv / Reboot OK
#PV 43,2 kWh Akku; 3x VE MP2 5000; 6,7 kWp > 18 Panele an 4x HM1500 + 1 HM800 WR; Open-DTU
#1 Timberwolf 2600 Velvet Red TWS #225 / VPN aktiv / Reboot OK
#2 Timberwolf 2600 Organic Silver TWS #438 / VPN aktiv / Reboot OK
#PV 43,2 kWh Akku; 3x VE MP2 5000; 6,7 kWp > 18 Panele an 4x HM1500 + 1 HM800 WR; Open-DTU
-
bluegaspode
- Beiträge: 84
- Registriert: Sa Nov 09, 2019 10:09 pm
- Hat sich bedankt: 7 Mal
- Danksagung erhalten: 34 Mal
Ich habe eines geöffnet.devilchris hat geschrieben: ↑Mo Dez 15, 2025 9:09 pm @bluegaspode schade das es so geendet ist mit deinem Server. Das Angebot ein Ticket zu eröffnen wurde ja unterbreitet hier hätte man bestimmt eine Lösung finden können.
Die Kondition ist, dass ich ins Risiko gehe ob Elabnet der Meinung ist, dass dieser Fehler durch mich verursacht wurde oder durch Elabnet.
Wenn elabnet der Meinung ist, es ist mein Fehler kostet
"Die Überprüfung der Funktion und ggfls. Erstellung eines Kostenvoranschläge" 119€. Zzgl Reparatur, also vermutlich aufspielen eines neuen Image für nach Erfahrungswerten von elabnet insgesamt 199€.
Ich habe die Hinweise von Stefan weiter oben wie 'ist evtl einer deiner Docker Container' und 'du hast die Notification nicht gesehen' so interpretiert, dass das eher als Fehler bei mir und weniger als möglicher Serienfehler in elabnets Softwarestack gesehen wird.
Formal finde ich es verständlich dass für ein Gerät außerhalb der Wartung ein Preis aufgerufen wird (und die potentiellen Kosten sind in der Mail transparent dargestellt worden).
Die 199€ waren es mir dann aber nicht wert.
Ich bin halt nur betrübt, dass es keine Möglichkeit der eigenen Rettung gibt, z. B sowas wie ein 'Rescue Mode' oder Zugriff auf die Docker Volumens per SSH wenn die Wahrscheinlichkeit gegeben ist, dass diese die Platte voll machen.
Zuletzt geändert von bluegaspode am So Dez 21, 2025 1:27 am, insgesamt 1-mal geändert.
"TWS 350Q ID:417, VPN geschlossen, Reboot nicht erlaubt"
-
StefanW
- Elaborated Networks

- Beiträge: 11139
- Registriert: So Aug 12, 2018 9:27 am
- Wohnort: Frauenneuharting
- Hat sich bedankt: 5480 Mal
- Danksagung erhalten: 9563 Mal
- Kontaktdaten:
Hallo Stefan,
Das "unbedarft falsch benutzt" ist etwas polemisch. Zum einen wissen wir nicht, was Ursache ist, zum anderen wäre ein - theoretisch denkbares - Vollschreiben durch eine Software im Docker Container nicht unbedarft, weil wir ausdrücklich und sehr explizit davor warnen und die Haftung dafür dann beim Nutzer ist.
Für alle Mitleser hier die Warnung, die automatisch eingeblendet wird (diese Warnung klappt erst nach Bestätigung ein):

Zusätzlich steht in der aufklappbaren Online Hilfe (vorletzter Absatz)
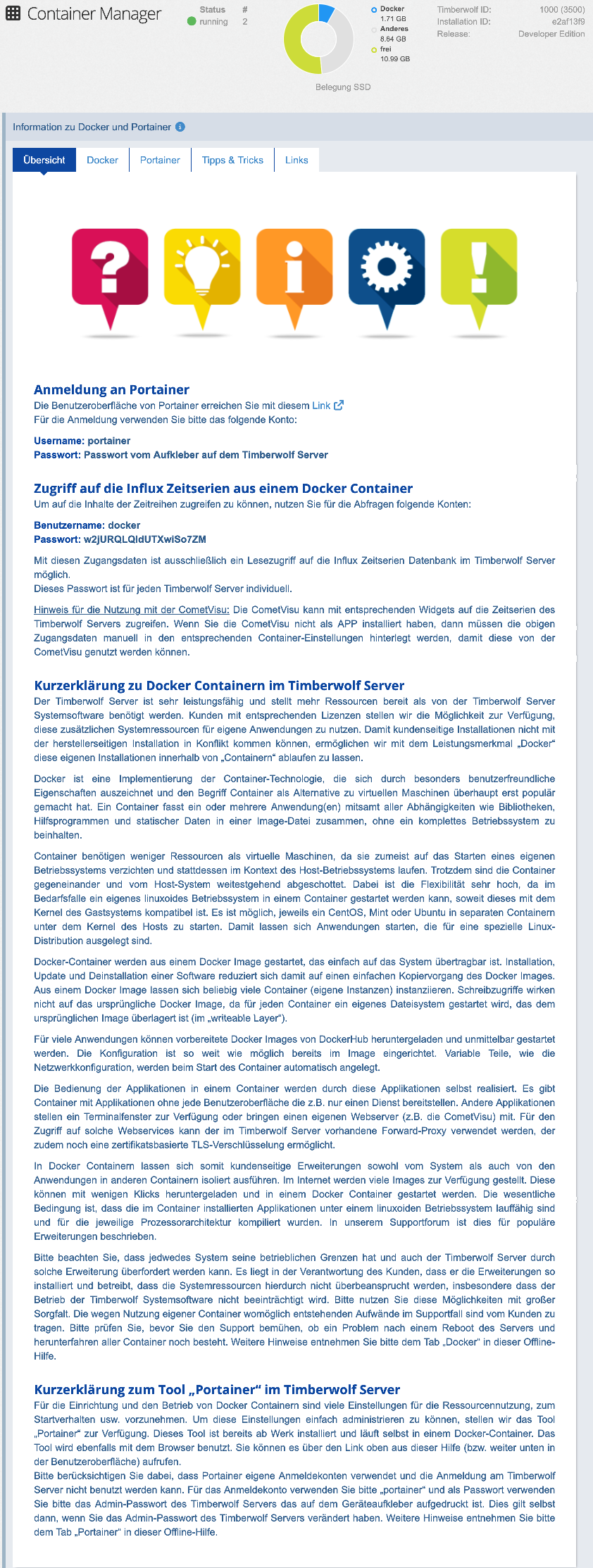
Von "unbedarft" kann nicht die Rede sein, es wird sehr klar darauf hingewiesen.
Ein Timberwolf Server ist - wie jedes andere IT-System - entweder Produktiv oder im Test.
Zu sagen, der eine Teil des Servers läuft produktiv und der andere Teil wäre nur im "Test", wenn dieser Teil technisch in der Lage ist, den produktiven Teil durch Übernutzung der Ressourcen zu stören, fällt nicht unter "Test". So wie es ein bisschen Schwanger auch nicht gibt.
Die Warnungen wurden glasklar gegeben. Wir bieten den Kunden diese Möglichkeit, weil es deren Server ist. Den dürften Sie benutzen wie sie möchten, das schließt eine Übernutzung der Ressourcen ein. Freie Fahrt für freie Bürger soweit das nur geht. Aber man muss dann auch Verantwortung übernehmen für sein handeln.
Ein IT System benötigt zum Ausführen der Firmware ausreichend Hardware-Ressourcen. Wenn diese Ressourcen - aus welchem Grund auch immer - nicht mehr bestehen, ist eine vollständige Ausführung aller Funktionen nicht mehr möglich. Das gilt für jedes IT System. Es ist deshalb nicht bricked, sondern benötigt eben einen Experteneingriff.
1. Alle Server der Modellreihe 3500 (mithin seit Dezember 2021) sind gegen das Vollschreiben durch Container geschützt, weil wir hier das Systemdesign geändert haben (Container laufen im User Space). Ein Update der früheren Modellreihen war nicht möglich.
2. ALLE Server aller Modellreihen seit 2019 haben einen Recovery Modus, der Remote genutzt werden kann. Die Besitzer der wenigen Server (Baureihe 2xxx) von vor 2019 (das genau Datum habe ich jetzt nicht) die diesen Modus noch nicht hatten, wurden damals angeschrieben, dass sie den Server einsenden sollen und es eine kostenfreie Nachinstallation gibt, so dass auch diese diesen Recovery Modus haben. Dein Server sollte einen solchen Revocery Modus haben, der auch funktionieren dürfte, solange es keinen HW Defekt gibt.
Bitte behaupte doch nicht einfach etwas, nur aus der Vermutung heraus.
Technisch können die Timberwolf Server dringende Meldungen des Betriebssystems in ein zentrales Log auf unseren Servern schreiben. Damit würde sich erkennen lassen, wenn eine neue Firmware z.B. "faul" wäre, weil plötzlich überall die CPU-Nutzung massiv ansteigt. Aber es sind halt Betriebssystem-Logs und wer soetwas schonmal gesehen hat, der weiß, dass da auch schonmal hunderte Warnmeldungen hintereinander im Sekunden-Abstand kommen können. Das kann man nicht so einfach an die Kunden rausschreiben.
Man müsste also schon sehr intelligent filtern, damit die Kunden keine Mailflut bekommen. Dabei ist aber die Frage, wie oft informiert man? Sendet man ein "Warnung aufgehoben" E-Mail wenn der Fehler weg ist. Wann warnt man erneut? Soll man einen Bestätigungs-Button ins E-Mail einbaut, damit man weniger erneute Warnungen schickt?
Und wenn man damit anfängt, dann erwarten die Kunden, dass man sie vor allem schützt. Also auch bei Übertemperatur? Kann nerven, wenn es halt warm ist dort und die Temperatur immer um 2K um eine Schwelle schwankt.
Das ist dann nicht mehr nur ein Script, sondern schon aufwändiger und dann muss man prüfen, dass diese Prüfungen laufen.
Kurz, wir sind auf Implementierungskosten in der Größenordnung eines hohen vierstelligen bis unteren fünfstelligen Betrag für die Einrichtung gekommen und einen jährlichen Aufwand im unteren vierstelligen Bereich.
Auf 15 Jahre hochgerechnet also durchaus ein ansehnlicher Betrag. Und für was? Für etwa ein Inzident pro Jahr über die gesamte Flotte. Mit stark fallender Tendenz, denn die Probleme sind vor allem mit Edomi-Container aufgetreten (wegen dessen Buslogs und täglichen Backups ohne automatischem Management seitens Edomi) und den alten Servermodelle die einen immer geringeren Anteil an der Flotte haben.
Ein solcher finanzieller Aufwand für diese geringe Anzahl von Vorkommnissen ist schwer begründbar. Nicht weil wir das nicht machen würden, sondern weil uns das nicht bezahlt wird.
Ohnehin werden alle anderen schreibenden Prozesse automatisch gemanaged. Es ist nicht möglich, mit Zeitserien, Buslogs, Dr.Modus-Monitoring und sonstigen Logs den Server vollzuschreiben, weil diese Daten automatisch gekürzt werden, weit bevor es knapp würde.
Zudem haben wir mit der letzten Firmware ein Ressourcenmonitoring eingebaut, dass die Daten in eine Zeitserie schreibt. Man kann sich damit selbst i Grafana einen Alarm setzen:
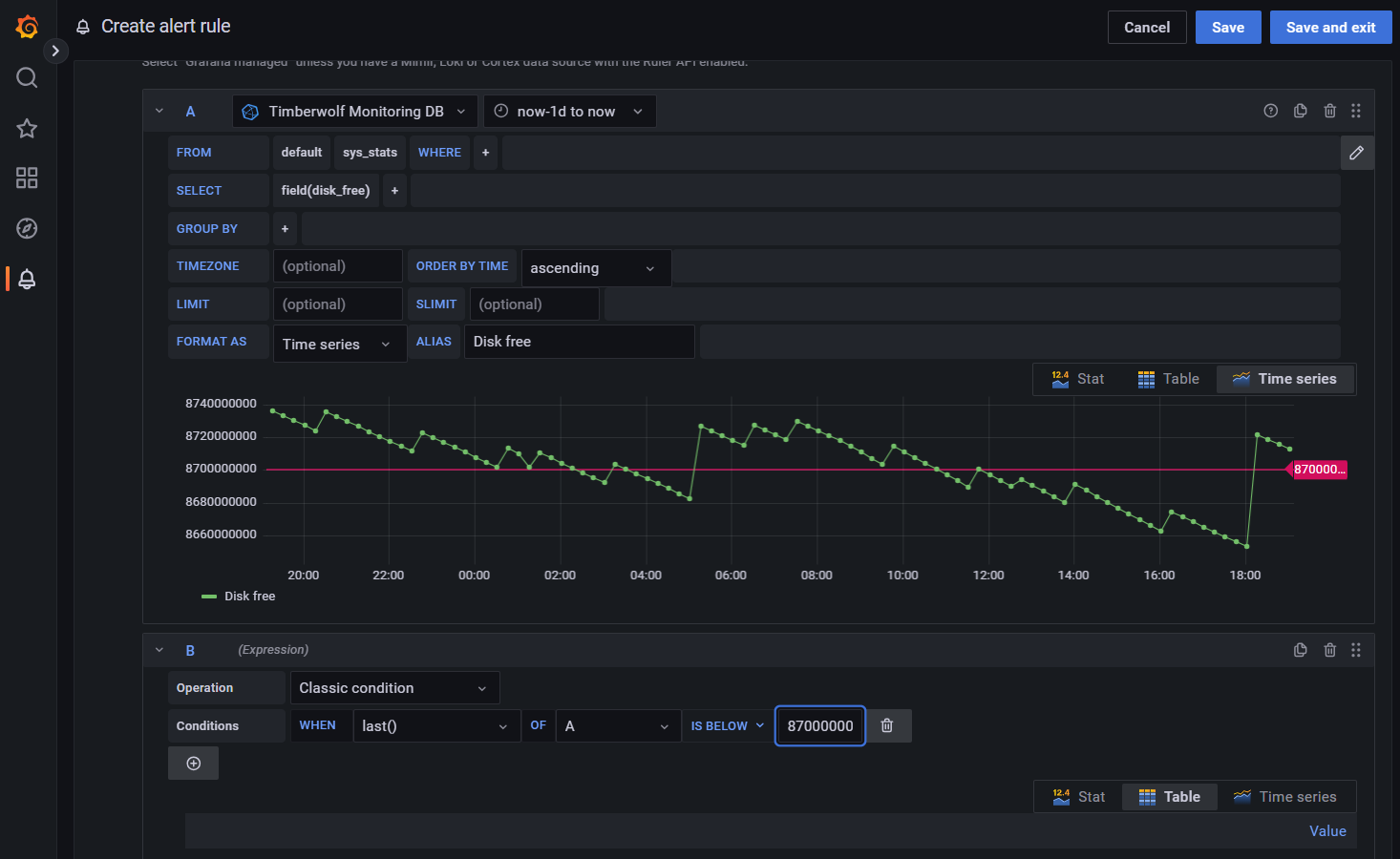
Der Server schützt sich selbst vor Übernutzung von Ressourcen seiner Prozesse und Funktionen im Rahmen seiner Firmware.
Im Falle eines Überschreibens durch Docker liegt eine Übernutzung der Ressourcen vor und kein normaler Betrieb. Wer mit seinem (Verbrenner-Schalt-Auto) im zweiten Gang 80 auf der Autobahn fährt, nutzt das Getriebe auch nicht mehr mit der vorgesehenen Geschwindigkeit für diese Schaltstufe. Ist auch nicht der Hersteller schuld.
Wenn jemand irgendeine Software installiert, welche die Ressourcen übernutzt, dann liegt das nicht nur in der Freiheit des Nutzers, sondern auch in dessen Verantwortung. Es obliegt ihm, die von ihm gewählte oder von ihm geschriebene Software sorgfältig auszuwählen für die zur Verfügung stehenden technischen Ressourcen und den Betrieb zu managen.
Wer sich bei seinem Timberwolf Server seine Platte überschreibt und einen Wartungsvertrag bei uns hat (oder ein Unterstützer ist), der krakeelt nicht im Forum herum, sondern meldet sich bei uns. Er bekommt dann Dateien für einen "Rescue-Stick" und den steckt er in den Server ein und bootet diesen. Auf dem Rescue-Stick ist die Anweisung an das Rescue System (befindet sich auf der unabhängigen Rescue Partition) dass ein Rescue VPN zu uns aufgebaut werden soll. Dann verbinden wir uns und nach ein paar Minuten löschen wir - nach Rücksprache mit dem Kunden - das entsprechenden Docker Volume, starten neu und alles läuft wieder.
Wir haben damit einen Service, den kein anderer Hersteller auf dem Markt bietet. Wir lassen unsere zahlenden Kunden selbstverständlich nicht im Stich.
Lieber Stefan, ich möchte Dich auf die Forenregeln hinweisen. Die oberste Regel ist, dass wir hier wohlwollend miteinander umgehen. Das ist mit Behauptungen und Vorwürfen, die nicht der Realität entsprechen, nicht gegeben.
Nebenbei ist das Zeitverschwendung für alle Beteiligten und sagt am Ende mehr über Dich aus, als über uns.
Bleib doch bitte beim Sachthema. Dein Server geht nicht mehr, was bedauerlich ist. Auf Deine Meldung im Forum von Montag kurz vor Mitternacht, wurde am Folgetag um kurz vor Neun reagiert, also in unter einer Stunde bei regulärer Arbeitszeit und Du wurdest gebeten, ein Ticket zu eröffnen.
Gegen Mittag haben wir dann schon eine erste Diagnose geliefert, damit waren dann drei Mitarbeiter mit dem Fall beschäftigt und es sind damit schon Kosten von kalkulatorisch etwa 150.- EUR aufgelaufen. Unser Bemühen findet in Deinem Vortrag keinerlei Wertung, womit Deine Kritik nicht nur unangemessen, sondern auch einseitig ist.
Ein bisschen mehr Fairness wäre nicht unangebracht. Wir wollten wirklich helfen.
Und gleich noch auf Dein zweites Nachtreten:
Es war in der Vergangenheit nur so, dass wenn die Platte vollgeschrieben war (die wenigen Male, wo das passiert ist), dann war es ein Docker Container (zu 90% Edomi). Was bei Deinem Server vorliegt, wissen wir nicht. Dass wir im zentralen Log einen Hinweis auf knappen freien Speicher gefunden haben, muss nicht die Ursache sein, es mag ja auch ein Überspannungsschaden sein (der dauert nur Millionstel Sekunden, das bekommt man nicht mit) oder der Flash ist ausgefallen (rein theoretisch, gab es noch nie, wir haben extra Industrial Grade pSLC verbaut).
In diesem Jahr gab es einen Kunden mit einem 6 Jahre alten Server, dessen Installation defekt war. Wir haben festgestellt, dass dies auf einem uralten Fehler in der Software beruht, den wir vor fünf Jahren schon gefixed haben. Der Kunde hat nur nie ein Update installiert (sieht man auch selten). Auch kein Wartungsvertrag, die Garantie also vor vier Jahren abgelaufen. Jetzt hätten wir schon sagen können, dass es in der Pflicht des Kunden ist, regelmäßige Updates einzuspielen (und das entspricht auch der Rechtsprechung). Trotzdem haben wir hier auf Kulanz erkannt und nichts berechnet, weil das war damals unser Fehler. Leider berichtet über sowas kein Kunde.
Dass Du uns nicht vertraust, ist Deine Entscheidung.
Diejenigen die Docker nutzen, können sich auf dem Timberwolf Server einen SSH-Docker einrichten, diesem alle Docker Volumes mit zuweisen und könnten dann darauf per SSH zugreifen und Ihre Volumes warten, selbst wenn man sich am Hauptsystem nicht mehr anmelden kann. Aber das muss man sich dann halt auch so einrichten, das obliegt dem Nutzer selbst. Es gibt auch eine Anleitung im Forum dafür. Hast Du halt nicht gemacht, was ok ist, aber es ist auch nicht unsere Schuld.
Ich finde es unfair, im Falle eines Problemes alle möglichen Ansprüche zu stellen, deren Erfüllung man vorher nicht finanziert hätte. Der Server kostet eben 1.000.- EUR und nicht 4.000 EUR um sämtliche Wünsche abzudecken. Es ist leicht, sich in der Phantasie vorzustellen, was man alles gerne hätte, dass in einem technischen System alles eingebaut ist. In der Realität ist das limitiert, weil auch der Preis limitiert sein soll.
Sei bitte Fair mit uns.
lg
Stefan
Wir wissen nicht ob der Server gebrickt ist. Du kannst Dich nicht anmelden, weil der Anmeldeservice nicht lädt, anderes kann durchaus funktionieren. In einem Log haben wir eine Warnung auf eine voll werdende Platte. Ob dies die Ursache ist, kann man nicht abschließend sagen, auch wenn es eine gewisse Wahrscheinlichkeit gibt.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pmMich hats letzte Woche echt auf kaltem Fuß erwischt, dass euer Server gebrickt werden kann, wenn man ihn unbedarft falsch benutzt.
Das "unbedarft falsch benutzt" ist etwas polemisch. Zum einen wissen wir nicht, was Ursache ist, zum anderen wäre ein - theoretisch denkbares - Vollschreiben durch eine Software im Docker Container nicht unbedarft, weil wir ausdrücklich und sehr explizit davor warnen und die Haftung dafür dann beim Nutzer ist.
Für alle Mitleser hier die Warnung, die automatisch eingeblendet wird (diese Warnung klappt erst nach Bestätigung ein):
Zusätzlich steht in der aufklappbaren Online Hilfe (vorletzter Absatz)
Von "unbedarft" kann nicht die Rede sein, es wird sehr klar darauf hingewiesen.
Schicke uns das Gerät ein, dann sehen wir uns das an. Wir nehmen die Analyse kostenfrei vor, weil wir wollen das für uns wissen. Liegt der Fehler bei uns, reparieren wir den kostenlos, ansonsten kannst den Server dem Ersatzteillager spenden oder bekommst ihn zurück.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pmWir werden jetzt nicht mehr feststellen, ob irgendein 3 Jahre alter TestDocker die SDKarte vollgemacht hat oder es was anderes war.
Ein Timberwolf Server ist - wie jedes andere IT-System - entweder Produktiv oder im Test.
Zu sagen, der eine Teil des Servers läuft produktiv und der andere Teil wäre nur im "Test", wenn dieser Teil technisch in der Lage ist, den produktiven Teil durch Übernutzung der Ressourcen zu stören, fällt nicht unter "Test". So wie es ein bisschen Schwanger auch nicht gibt.
Die Warnungen wurden glasklar gegeben. Wir bieten den Kunden diese Möglichkeit, weil es deren Server ist. Den dürften Sie benutzen wie sie möchten, das schließt eine Übernutzung der Ressourcen ein. Freie Fahrt für freie Bürger soweit das nur geht. Aber man muss dann auch Verantwortung übernehmen für sein handeln.
Wir tun gar nichts.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pmIch habe gelernt, dass ihr bei so einem fatalen Fehlerbild "Server Bricked":
Ein IT System benötigt zum Ausführen der Firmware ausreichend Hardware-Ressourcen. Wenn diese Ressourcen - aus welchem Grund auch immer - nicht mehr bestehen, ist eine vollständige Ausführung aller Funktionen nicht mehr möglich. Das gilt für jedes IT System. Es ist deshalb nicht bricked, sondern benötigt eben einen Experteneingriff.
Das ist falsch.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pm- das Problem kennt, aber eure Systempartition nicht vor Überlauf schützt (oder einen Recovery Modus habt)
1. Alle Server der Modellreihe 3500 (mithin seit Dezember 2021) sind gegen das Vollschreiben durch Container geschützt, weil wir hier das Systemdesign geändert haben (Container laufen im User Space). Ein Update der früheren Modellreihen war nicht möglich.
2. ALLE Server aller Modellreihen seit 2019 haben einen Recovery Modus, der Remote genutzt werden kann. Die Besitzer der wenigen Server (Baureihe 2xxx) von vor 2019 (das genau Datum habe ich jetzt nicht) die diesen Modus noch nicht hatten, wurden damals angeschrieben, dass sie den Server einsenden sollen und es eine kostenfreie Nachinstallation gibt, so dass auch diese diesen Recovery Modus haben. Dein Server sollte einen solchen Revocery Modus haben, der auch funktionieren dürfte, solange es keinen HW Defekt gibt.
Bitte behaupte doch nicht einfach etwas, nur aus der Vermutung heraus.
Haben wir - mehrmals übrigens - erwogen und immer wieder hintenangestellt.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pm- ihr einen Push bekommt, wenn der Server kurz davor ist ein echtes Problem zu haben und daraus aber nichts macht, um den Kunden/das System zu schützen.
Technisch können die Timberwolf Server dringende Meldungen des Betriebssystems in ein zentrales Log auf unseren Servern schreiben. Damit würde sich erkennen lassen, wenn eine neue Firmware z.B. "faul" wäre, weil plötzlich überall die CPU-Nutzung massiv ansteigt. Aber es sind halt Betriebssystem-Logs und wer soetwas schonmal gesehen hat, der weiß, dass da auch schonmal hunderte Warnmeldungen hintereinander im Sekunden-Abstand kommen können. Das kann man nicht so einfach an die Kunden rausschreiben.
Man müsste also schon sehr intelligent filtern, damit die Kunden keine Mailflut bekommen. Dabei ist aber die Frage, wie oft informiert man? Sendet man ein "Warnung aufgehoben" E-Mail wenn der Fehler weg ist. Wann warnt man erneut? Soll man einen Bestätigungs-Button ins E-Mail einbaut, damit man weniger erneute Warnungen schickt?
Und wenn man damit anfängt, dann erwarten die Kunden, dass man sie vor allem schützt. Also auch bei Übertemperatur? Kann nerven, wenn es halt warm ist dort und die Temperatur immer um 2K um eine Schwelle schwankt.
Das ist dann nicht mehr nur ein Script, sondern schon aufwändiger und dann muss man prüfen, dass diese Prüfungen laufen.
Kurz, wir sind auf Implementierungskosten in der Größenordnung eines hohen vierstelligen bis unteren fünfstelligen Betrag für die Einrichtung gekommen und einen jährlichen Aufwand im unteren vierstelligen Bereich.
Auf 15 Jahre hochgerechnet also durchaus ein ansehnlicher Betrag. Und für was? Für etwa ein Inzident pro Jahr über die gesamte Flotte. Mit stark fallender Tendenz, denn die Probleme sind vor allem mit Edomi-Container aufgetreten (wegen dessen Buslogs und täglichen Backups ohne automatischem Management seitens Edomi) und den alten Servermodelle die einen immer geringeren Anteil an der Flotte haben.
Ein solcher finanzieller Aufwand für diese geringe Anzahl von Vorkommnissen ist schwer begründbar. Nicht weil wir das nicht machen würden, sondern weil uns das nicht bezahlt wird.
Ist 2021 bereits passiert. Die Modellreihe 3500 hat einen weitgehenden Schutz gegen Überschreibung der Platte.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pmIch wünsche dem nächsten Nutzer mit ähnlichem Fehlerbild der sich deutlich intensiver auf den Timberwolf eingelassen hat, dass elabnet hier prozessual oder SW-seitig nachbessert.
Ohnehin werden alle anderen schreibenden Prozesse automatisch gemanaged. Es ist nicht möglich, mit Zeitserien, Buslogs, Dr.Modus-Monitoring und sonstigen Logs den Server vollzuschreiben, weil diese Daten automatisch gekürzt werden, weit bevor es knapp würde.
Zudem haben wir mit der letzten Firmware ein Ressourcenmonitoring eingebaut, dass die Daten in eine Zeitserie schreibt. Man kann sich damit selbst i Grafana einen Alarm setzen:
Unsinn.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pmSowas kann RICHTIG böse ins Auge gehen und dann sitzt du da mit gebricktem Server
Der Server schützt sich selbst vor Übernutzung von Ressourcen seiner Prozesse und Funktionen im Rahmen seiner Firmware.
Im Falle eines Überschreibens durch Docker liegt eine Übernutzung der Ressourcen vor und kein normaler Betrieb. Wer mit seinem (Verbrenner-Schalt-Auto) im zweiten Gang 80 auf der Autobahn fährt, nutzt das Getriebe auch nicht mehr mit der vorgesehenen Geschwindigkeit für diese Schaltstufe. Ist auch nicht der Hersteller schuld.
Wenn jemand irgendeine Software installiert, welche die Ressourcen übernutzt, dann liegt das nicht nur in der Freiheit des Nutzers, sondern auch in dessen Verantwortung. Es obliegt ihm, die von ihm gewählte oder von ihm geschriebene Software sorgfältig auszuwählen für die zur Verfügung stehenden technischen Ressourcen und den Betrieb zu managen.
Für den Ehestress können wir nichts. Jedes technische Gerät kann ausfallen.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pma.k.a gebricktes Haus bei deinem 1.000€ Server und bekommst Ehestress, wenn du vielleicht noch elabnet Anleihen für weitere 1.000€ gekauft hast.
Wer sich bei seinem Timberwolf Server seine Platte überschreibt und einen Wartungsvertrag bei uns hat (oder ein Unterstützer ist), der krakeelt nicht im Forum herum, sondern meldet sich bei uns. Er bekommt dann Dateien für einen "Rescue-Stick" und den steckt er in den Server ein und bootet diesen. Auf dem Rescue-Stick ist die Anweisung an das Rescue System (befindet sich auf der unabhängigen Rescue Partition) dass ein Rescue VPN zu uns aufgebaut werden soll. Dann verbinden wir uns und nach ein paar Minuten löschen wir - nach Rücksprache mit dem Kunden - das entsprechenden Docker Volume, starten neu und alles läuft wieder.
Wir haben damit einen Service, den kein anderer Hersteller auf dem Markt bietet. Wir lassen unsere zahlenden Kunden selbstverständlich nicht im Stich.
Das ist Quatschjura. Niemand haftet irgendwie "lustig" weil ein technisches Gerät ausfällt. Egal ob das die KNX Spannungsversorung ist, ein Aktor, ein Glastaser, ein GIRA Homeserver oder ein Timberwolf Server. Allenfalls während der Gewährleistung muss es nach den gesetzlichen Regeln ersetzt oder repariert werden, sofern es ein Fehler ist, der bei der Übergabe schon im Gerätes vorhanden war. Bei der Auslieferung gibt es keine Docker Container die irgendwas anstellen. Und wenn ein Integrator darüber hinaus Garantien gibt, dann hat er ein zweites Gerät im Lager und uns auf Kurzwahl.bluegaspode hat geschrieben: ↑Mo Dez 15, 2025 5:22 pmOder lustige Haftungsfragen als Systemintegrator .
Lieber Stefan, ich möchte Dich auf die Forenregeln hinweisen. Die oberste Regel ist, dass wir hier wohlwollend miteinander umgehen. Das ist mit Behauptungen und Vorwürfen, die nicht der Realität entsprechen, nicht gegeben.
Nebenbei ist das Zeitverschwendung für alle Beteiligten und sagt am Ende mehr über Dich aus, als über uns.
Bleib doch bitte beim Sachthema. Dein Server geht nicht mehr, was bedauerlich ist. Auf Deine Meldung im Forum von Montag kurz vor Mitternacht, wurde am Folgetag um kurz vor Neun reagiert, also in unter einer Stunde bei regulärer Arbeitszeit und Du wurdest gebeten, ein Ticket zu eröffnen.
Gegen Mittag haben wir dann schon eine erste Diagnose geliefert, damit waren dann drei Mitarbeiter mit dem Fall beschäftigt und es sind damit schon Kosten von kalkulatorisch etwa 150.- EUR aufgelaufen. Unser Bemühen findet in Deinem Vortrag keinerlei Wertung, womit Deine Kritik nicht nur unangemessen, sondern auch einseitig ist.
Ein bisschen mehr Fairness wäre nicht unangebracht. Wir wollten wirklich helfen.
Und gleich noch auf Dein zweites Nachtreten:
Wie soll es auch anders gehen? Es ist Dein Server. Er gehört Dir mit allen Funktionen und Problemen. Wie beim Haarfön, der Mikrowelle und dem Kühlschrank auch. Reparaturen nach Ende der Gewährleistung sind nunmal in der Regel vom Kunden zu tragen. Wer das nicht möchte, kann einen Service-Vertrag abschließen.bluegaspode hat geschrieben: ↑So Dez 21, 2025 12:00 amDie Kondition ist, dass ich ins Risiko gehe ob Elabnet der Meinung ist, dass dieser Fehler durch mich verursacht wurde oder durch Elabnet.
Das ist Deine Interpretation. Tatsächlich wissen wir nicht, was hier Sache ist.bluegaspode hat geschrieben: ↑So Dez 21, 2025 12:00 amWenn elabnet der Meinung ist, es ist mein Fehler kostet.... Ich habe die Hinweise von Stefan weiter oben wie 'ist evtl einer deiner Docker Container' und 'du hast die Notification nicht gesehen' so interpretiert, dass das eher als Fehler bei mir und weniger als möglicher Serienfehler in elabnets Softwarestack gesehen wird.
Es war in der Vergangenheit nur so, dass wenn die Platte vollgeschrieben war (die wenigen Male, wo das passiert ist), dann war es ein Docker Container (zu 90% Edomi). Was bei Deinem Server vorliegt, wissen wir nicht. Dass wir im zentralen Log einen Hinweis auf knappen freien Speicher gefunden haben, muss nicht die Ursache sein, es mag ja auch ein Überspannungsschaden sein (der dauert nur Millionstel Sekunden, das bekommt man nicht mit) oder der Flash ist ausgefallen (rein theoretisch, gab es noch nie, wir haben extra Industrial Grade pSLC verbaut).
In diesem Jahr gab es einen Kunden mit einem 6 Jahre alten Server, dessen Installation defekt war. Wir haben festgestellt, dass dies auf einem uralten Fehler in der Software beruht, den wir vor fünf Jahren schon gefixed haben. Der Kunde hat nur nie ein Update installiert (sieht man auch selten). Auch kein Wartungsvertrag, die Garantie also vor vier Jahren abgelaufen. Jetzt hätten wir schon sagen können, dass es in der Pflicht des Kunden ist, regelmäßige Updates einzuspielen (und das entspricht auch der Rechtsprechung). Trotzdem haben wir hier auf Kulanz erkannt und nichts berechnet, weil das war damals unser Fehler. Leider berichtet über sowas kein Kunde.
Dass Du uns nicht vertraust, ist Deine Entscheidung.
Damit wäre es immer noch weniger als der Wiederverkaufswert. Weil 350er sind wegen des PBMs darin nachgefragt, weil wir derzeit keine PBMs mehr bauen.bluegaspode hat geschrieben: ↑So Dez 21, 2025 12:00 amFormal finde ich es verständlich dass für ein Gerät außerhalb der Wartung ein Preis aufgerufen wird (und die potentiellen Kosten sind in der Mail transparent dargestellt worden).
Die 199€ waren es mir dann aber nicht wert.
Es gibt einen Rescue Mode. Dieser ist Wartungsvertragskunden vorbehalten zur Nutzung durch unsere Experten. Wir können kein Root rausgeben damit die Kunden selbst am System herumfummeln, weil das ist sehr komplex. Das ist bei moderner Technik auch nicht mehr möglich. Ich habe bei meinem ersten Auto noch die Zündkerzen selbst gewechselt und am Vergaser geschraubt. Bei meinem Tesla rufe ich - falls was wäre - die Experten an, die sich dann remote mit dem Auto verbinden und ggfls. die Software fixen. Man schraubt bei modernen Produkten nicht mehr selbst - weil das Spezialwissen dafür fehlt.bluegaspode hat geschrieben: ↑So Dez 21, 2025 12:00 amIch bin halt nur betrübt, dass es keine Möglichkeit der eigenen Rettung gibt, z. B sowas wie ein 'Rescue Mode' oder Zugriff auf die Docker Volumens per SSH wenn die Wahrscheinlichkeit gegeben ist, dass diese die Platte voll machen.
Diejenigen die Docker nutzen, können sich auf dem Timberwolf Server einen SSH-Docker einrichten, diesem alle Docker Volumes mit zuweisen und könnten dann darauf per SSH zugreifen und Ihre Volumes warten, selbst wenn man sich am Hauptsystem nicht mehr anmelden kann. Aber das muss man sich dann halt auch so einrichten, das obliegt dem Nutzer selbst. Es gibt auch eine Anleitung im Forum dafür. Hast Du halt nicht gemacht, was ok ist, aber es ist auch nicht unsere Schuld.
Ich finde es unfair, im Falle eines Problemes alle möglichen Ansprüche zu stellen, deren Erfüllung man vorher nicht finanziert hätte. Der Server kostet eben 1.000.- EUR und nicht 4.000 EUR um sämtliche Wünsche abzudecken. Es ist leicht, sich in der Phantasie vorzustellen, was man alles gerne hätte, dass in einem technischen System alles eingebaut ist. In der Realität ist das limitiert, weil auch der Preis limitiert sein soll.
Sei bitte Fair mit uns.
lg
Stefan
Zuletzt geändert von StefanW am So Dez 21, 2025 9:06 pm, insgesamt 1-mal geändert.
Stefan Werner
Product Owner für Timberwolf Server, 1-Wire und BlitzART
Bitte WIKI lesen. Allg. Support nur im Forum. Bitte keine PN
Zu Preisen, Lizenzen, Garantie, HW-Defekt an service at elabnet dot de
Link zu Impressum und Datenschutzerklärung oben.
Product Owner für Timberwolf Server, 1-Wire und BlitzART
Bitte WIKI lesen. Allg. Support nur im Forum. Bitte keine PN
Zu Preisen, Lizenzen, Garantie, HW-Defekt an service at elabnet dot de
Link zu Impressum und Datenschutzerklärung oben.
-
bluegaspode
- Beiträge: 84
- Registriert: Sa Nov 09, 2019 10:09 pm
- Hat sich bedankt: 7 Mal
- Danksagung erhalten: 34 Mal
Es ist echt toll, wie hier der "Strohmann" des falsch benutzten Docker Containers so schön ausgeschlachtet wird.
Ist ja dann auch leicht damit die Verantwortung auf mich zu schieben.
Fürs Protokoll: auf einem 350Q läuft Dockertechnisch doch 'nüscht'. Schon gar nicht edomi (schon technisch nicht, weil der 350Q Arm basiert ist). Wenn wir über einen "Test-Docker" reden, dann war das die CometVisu aus dem TW AppStore damals von vor 5 Jahren.
Ich sehe aber ein, dass ich bei dieser Hochrisikoanwendung nicht bedacht habe, dass das (vielleicht?) Ursache eine Serverfails 5 Jahre später sein könnte. Ich habe mithin "irgendeine Software installiert, welche die Ressourcen übernutzt" und deswegen "liegt das nicht nur in der Freiheit" von mir "sondern auch in meiner Verantwortung."
Ich habe verstanden und nehme die Schuld auf mich und lebe mit den Konsequenzen.
Bei einer Nachricht mit Verweis auf den 3500er habe ich jetzt das Gefühl dass ich "selber schuld" bin, dass ich nicht 2 Jahre später gleich den nächsten Server gekauft habe, der viel besser ist.
- ich habe hier in diesem Thread gefragt, was man machen kann und ob es eine Alternative zum einschicken gibt.
- ich habe ein Support-Ticket geöffnet
Keiner hat angeboten, den potentiell verfügbaren Remote Recovery Modus zu nutzen.
Du zauberst argumentativ diese Möglichkeit jetzt magisch hervor, damit dein Post besser funktioniert und du mir was vorwerfen kannst (genau wie die Referenzen auf den 3500er Server)
Mir vorgeschlagen (sowohl von dir hier im Thread als auch im Support-Ticket) wurde ein aufwändiger Prozess mit:
- Server ausbauen / einschicken / zurückschicken / Server einbauen / Achtung: danach gelöschter Server -> Server neu einrichten / Achtung: Postlaufzeiten / Achtung: Reparaturkosten
Ich kann nicht hellsehen, dass es alternative schlankere Prozesse gibt, die beiden Seiten weniger Arbeit gemacht hätten und auch schneller gewesen wären. In der Konsequenz hat dieser vorgeschlagene Ablauf aber auch zu meinem Entschluss am letzten Wochenende geführt den ich hier dann nochmal kommuniziert habe.
Dass du mit "fehlendes Vertrauen" hier argumentierst empört mich enorm. Wer die Server 2019 gekauft hat, in Zeiten wo die erste Sanierung gerade halbwegs durch war und VIEL auf Basis der Roadmap und versprochenen Features lief ... auch lassen wir das.
Mit dem Wissen dass ihr regelmäßig aus Gründen sehr genau auf euren Umsatz guckt, hatte ich keinen Indiz, dass in irgendeiner Form Kulanz gewährt wird.
Mein Post vom 15.12. ist dann die Zusammenfassung und Entscheidung aus meiner Perspektive.
Ich habe allein auf die von euch zur Verfügung gestellten Informationen und Handlungsvorschläge reagiert und daraus Rückschlüsse und Beobachtungen gezogen. Dass du bestimmte meiner "Behauptungen" mit dem 3500er Server von 2021 wiederlegen kannst - das ist dein argumentativer Trick (in der Fachsprache ein "Strohman"-Argument").
Dass wir nicht mehr zusammengefunden haben, liegt wohl daran, dass der pragmatische Vorschlag: "wir könnten dir USB-Stick anbieten und Remote draufgucken" irgendwie nicht kam.
Die Folge war, dass ich in jedem Fall den Server hätte ausbauen müssen, realistisch mit mind. 5 Tage (Post)Laufzeit hätte rechnen müssen und 200€ Kosten im Raum standen, ohne Indiz ob das eher auf Kulanz hinausläuft oder nicht. Und das während die Automationen/Visu eines anderen Systems nicht mehr liefen, weil auch der KNX-Router im TW seinen Dienst eingestellt hatte (erst später festgestellt)
Mit dem Ausblick den Server in jedem Fall ausbauen zu müssen, war der Entschluss dann klar: dann ziehe ich den Ausbau jetzt richtig durch.
Die Aufwand/Kosten/Nutzen Rechnung ging mit dem zur Verfügung gestellten Wissen nicht auf.
Grüße
Stefan
Ist ja dann auch leicht damit die Verantwortung auf mich zu schieben.
Fürs Protokoll: auf einem 350Q läuft Dockertechnisch doch 'nüscht'. Schon gar nicht edomi (schon technisch nicht, weil der 350Q Arm basiert ist). Wenn wir über einen "Test-Docker" reden, dann war das die CometVisu aus dem TW AppStore damals von vor 5 Jahren.
Ich sehe aber ein, dass ich bei dieser Hochrisikoanwendung nicht bedacht habe, dass das (vielleicht?) Ursache eine Serverfails 5 Jahre später sein könnte. Ich habe mithin "irgendeine Software installiert, welche die Ressourcen übernutzt" und deswegen "liegt das nicht nur in der Freiheit" von mir "sondern auch in meiner Verantwortung."
Ich habe verstanden und nehme die Schuld auf mich und lebe mit den Konsequenzen.
Wie konnte ich auch so fahrlässig sein, den Server schon 2019 zu kaufen.
Bei einer Nachricht mit Verweis auf den 3500er habe ich jetzt das Gefühl dass ich "selber schuld" bin, dass ich nicht 2 Jahre später gleich den nächsten Server gekauft habe, der viel besser ist.
- mein Server ist von Late 2019, könnte/müsste das deiner Aussage also habenALLE Server aller Modellreihen seit 2019 haben einen Recovery Modus, der Remote genutzt werden kann. [...] Dein Server sollte einen solchen Revocery Modus haben, der auch funktionieren dürfte, solange es keinen HW Defekt gibt.
Bitte behaupte doch nicht einfach etwas, nur aus der Vermutung heraus.
- ich habe hier in diesem Thread gefragt, was man machen kann und ob es eine Alternative zum einschicken gibt.
- ich habe ein Support-Ticket geöffnet
Keiner hat angeboten, den potentiell verfügbaren Remote Recovery Modus zu nutzen.
Du zauberst argumentativ diese Möglichkeit jetzt magisch hervor, damit dein Post besser funktioniert und du mir was vorwerfen kannst (genau wie die Referenzen auf den 3500er Server)
Wenn ihr diese Möglichkeiten habt UND der erste Verdacht die volle SSD ist, warum bietet ihr das nicht an?Wer sich bei seinem Timberwolf Server seine Platte überschreibt und einen Wartungsvertrag bei uns hat (oder ein Unterstützer ist) [...] bekommt dann Dateien für einen "Rescue-Stick" [...] dass ein Rescue VPN zu uns aufbaut [...] dann verbinden wir uns und nach ein paar Minuten löschen wir - nach Rücksprache mit dem Kunden - das entsprechenden Docker Volume, starten neu und alles läuft wieder.
Wir haben damit einen Service, den kein anderer Hersteller auf dem Markt bietet. Wir lassen unsere zahlenden Kunden selbstverständlich nicht im Stich.
Mir vorgeschlagen (sowohl von dir hier im Thread als auch im Support-Ticket) wurde ein aufwändiger Prozess mit:
- Server ausbauen / einschicken / zurückschicken / Server einbauen / Achtung: danach gelöschter Server -> Server neu einrichten / Achtung: Postlaufzeiten / Achtung: Reparaturkosten
Ich kann nicht hellsehen, dass es alternative schlankere Prozesse gibt, die beiden Seiten weniger Arbeit gemacht hätten und auch schneller gewesen wären. In der Konsequenz hat dieser vorgeschlagene Ablauf aber auch zu meinem Entschluss am letzten Wochenende geführt den ich hier dann nochmal kommuniziert habe.
Dass du mit "fehlendes Vertrauen" hier argumentierst empört mich enorm. Wer die Server 2019 gekauft hat, in Zeiten wo die erste Sanierung gerade halbwegs durch war und VIEL auf Basis der Roadmap und versprochenen Features lief ... auch lassen wir das.
Mit dem Wissen dass ihr regelmäßig aus Gründen sehr genau auf euren Umsatz guckt, hatte ich keinen Indiz, dass in irgendeiner Form Kulanz gewährt wird.
Bitte lies dir den Thread von vorne durch. Bis 09.12. habe ich Rückfragen gestellt und dann ein Support-Ticket erstellt.Lieber Stefan, ich möchte Dich auf die Forenregeln hinweisen. Die oberste Regel ist, dass wir hier wohlwollend miteinander umgehen. Das ist mit Behauptungen und Vorwürfen, die nicht der Realität entsprechen, nicht gegeben.
Mein Post vom 15.12. ist dann die Zusammenfassung und Entscheidung aus meiner Perspektive.
Ich habe allein auf die von euch zur Verfügung gestellten Informationen und Handlungsvorschläge reagiert und daraus Rückschlüsse und Beobachtungen gezogen. Dass du bestimmte meiner "Behauptungen" mit dem 3500er Server von 2021 wiederlegen kannst - das ist dein argumentativer Trick (in der Fachsprache ein "Strohman"-Argument").
Dann fassen wir zusammen:Gegen Mittag haben wir dann schon eine erste Diagnose geliefert, damit waren dann drei Mitarbeiter mit dem Fall beschäftigt und es sind damit schon Kosten von kalkulatorisch etwa 150.- EUR aufgelaufen. Unser Bemühen findet in Deinem Vortrag keinerlei Wertung, womit Deine Kritik nicht nur unangemessen, sondern auch einseitig ist.
Dass wir nicht mehr zusammengefunden haben, liegt wohl daran, dass der pragmatische Vorschlag: "wir könnten dir USB-Stick anbieten und Remote draufgucken" irgendwie nicht kam.
Die Folge war, dass ich in jedem Fall den Server hätte ausbauen müssen, realistisch mit mind. 5 Tage (Post)Laufzeit hätte rechnen müssen und 200€ Kosten im Raum standen, ohne Indiz ob das eher auf Kulanz hinausläuft oder nicht. Und das während die Automationen/Visu eines anderen Systems nicht mehr liefen, weil auch der KNX-Router im TW seinen Dienst eingestellt hatte (erst später festgestellt)
Mit dem Ausblick den Server in jedem Fall ausbauen zu müssen, war der Entschluss dann klar: dann ziehe ich den Ausbau jetzt richtig durch.
Die Aufwand/Kosten/Nutzen Rechnung ging mit dem zur Verfügung gestellten Wissen nicht auf.
Grüße
Stefan
"TWS 350Q ID:417, VPN geschlossen, Reboot nicht erlaubt"
-
StefanW
- Elaborated Networks
- Beiträge: 11139
- Registriert: So Aug 12, 2018 9:27 am
- Wohnort: Frauenneuharting
- Hat sich bedankt: 5480 Mal
- Danksagung erhalten: 9563 Mal
- Kontaktdaten:
Lieber Stefan,
es tut mir sehr leid, dass wir Deine Anforderungen nicht erfüllen.
Ich löse lieber Probleme als die Schuldfrage. Wenn Du Dich auch dafür entscheiden möchtest, dann schreibe uns bitte an das Ticket.
Lösungsvorschläge hast Du erhalten.
Ich wünsche ein frohes Weihnachtsfest und falls wir uns nicht mehr hören, einen guten Rutsch ins neue Jahr.
Stefan
es tut mir sehr leid, dass wir Deine Anforderungen nicht erfüllen.
Ich löse lieber Probleme als die Schuldfrage. Wenn Du Dich auch dafür entscheiden möchtest, dann schreibe uns bitte an das Ticket.
Lösungsvorschläge hast Du erhalten.
Ich wünsche ein frohes Weihnachtsfest und falls wir uns nicht mehr hören, einen guten Rutsch ins neue Jahr.
Stefan
Stefan Werner
Product Owner für Timberwolf Server, 1-Wire und BlitzART
Bitte WIKI lesen. Allg. Support nur im Forum. Bitte keine PN
Zu Preisen, Lizenzen, Garantie, HW-Defekt an service at elabnet dot de
Link zu Impressum und Datenschutzerklärung oben.
Product Owner für Timberwolf Server, 1-Wire und BlitzART
Bitte WIKI lesen. Allg. Support nur im Forum. Bitte keine PN
Zu Preisen, Lizenzen, Garantie, HW-Defekt an service at elabnet dot de
Link zu Impressum und Datenschutzerklärung oben.
-
bluegaspode
- Beiträge: 84
- Registriert: Sa Nov 09, 2019 10:09 pm
- Hat sich bedankt: 7 Mal
- Danksagung erhalten: 34 Mal
Hallo Stefan,
Ich habe deinen letzten Post mit folgendem Prompt an 2 LLMs gegeben (ChatGPT Pro / Gemini) um für mich rauszufinden, ob ich zu sensibel oder emotional reagiere.
"Bewerte diesen Post hinsichtlich Tonalität und versteckten, evtl. missinterpretierbaren Formulierungen."
Ich fühle mich von der Einordnung in meiner Erstwahrnehmung bestätigt und werde keine weitere Energie zum Server mehr investieren.
Ich wünsche dir und allen Mitlesern ein frohes Fest und einen guten Rutsch.
Zuletzt geändert von bluegaspode am Mo Dez 22, 2025 1:46 pm, insgesamt 1-mal geändert.
"TWS 350Q ID:417, VPN geschlossen, Reboot nicht erlaubt"
-
StefanW
- Elaborated Networks
- Beiträge: 11139
- Registriert: So Aug 12, 2018 9:27 am
- Wohnort: Frauenneuharting
- Hat sich bedankt: 5480 Mal
- Danksagung erhalten: 9563 Mal
- Kontaktdaten:
Hallo AndererStefan,
ich möchte noch Deine Fragen beantworten
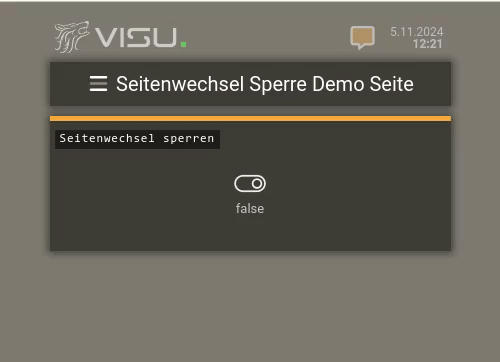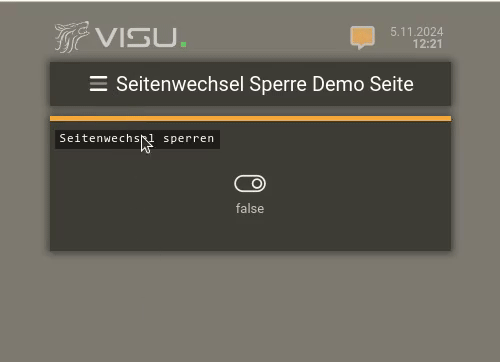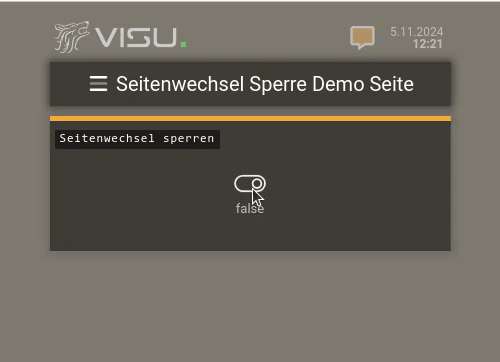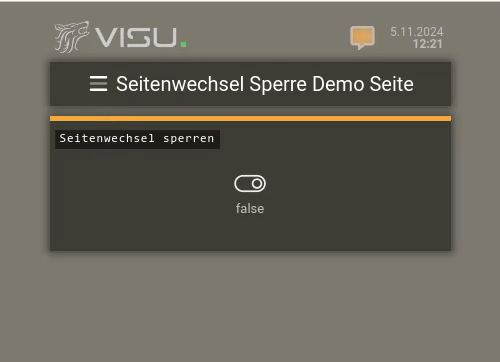
Hier in diesem Video (in dem es um Seitenwechsel-Sperren geht) sieht man oben rechts das Notification-Icon blinken:
Wenn man dort klickt / touched, dann bekommt man die Nachrichten in der VISU zu sehen:

Hinweis: Zusätzlich kann man aus der Logik auch eigene Nachrichten an das Nachrichtencenter senden (im Bild ist das die obere "Wichtige Nachricht")

Letztlich sind das automatisch angelegte Zeitserien, die man mit Klick auf das Grafana Symbol auch dort sehen kann (hier über 30 Tage):
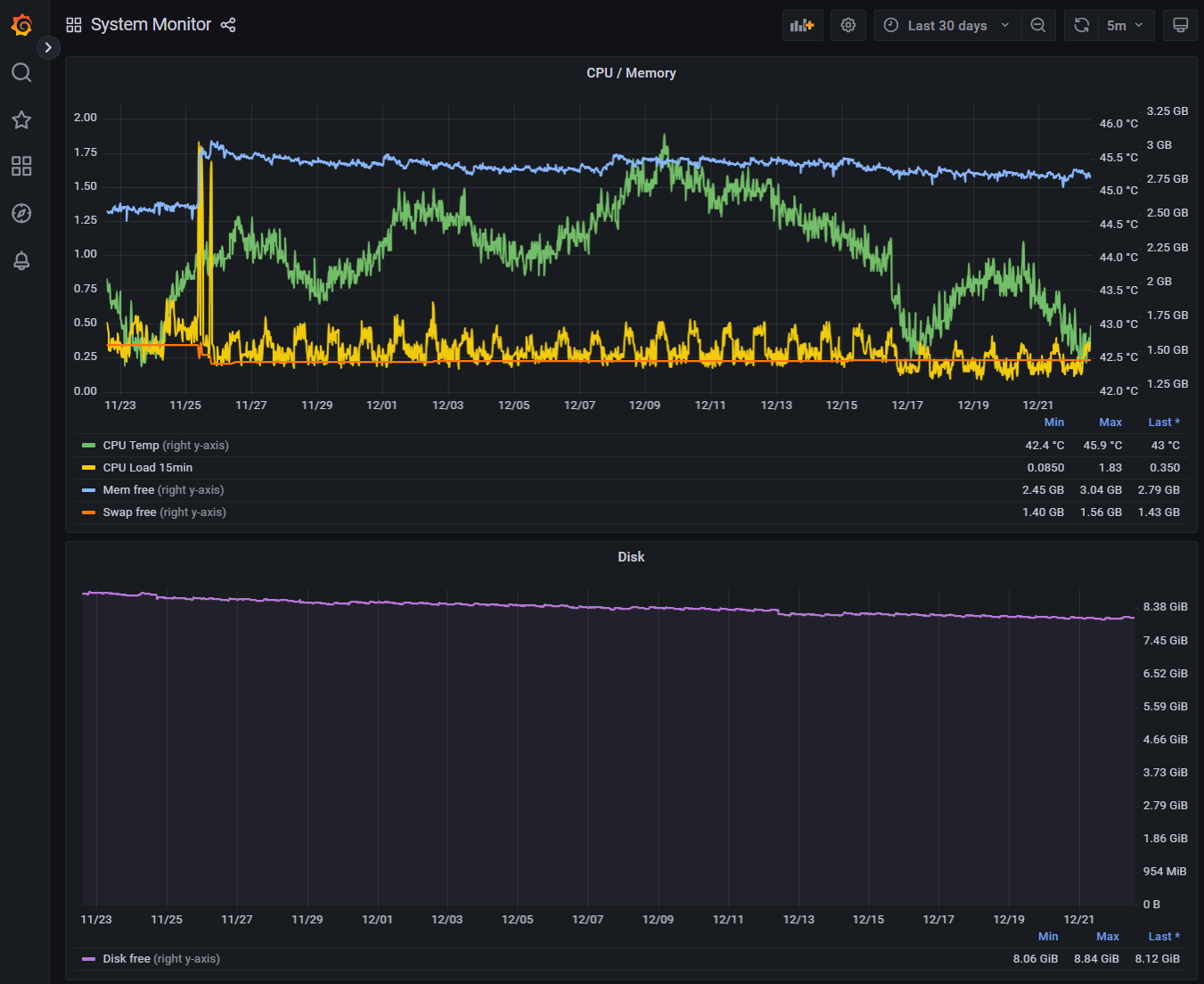
Hinweis: Diese Zeitserien kann man auch in einem Widget auf der VISU anzeigen lassen.
Hinweis: Auf unserer Liste steht, dass wir diese Systemdaten auch als Systemobjekt zur Verfügung stellen, so dass man diese Systemdaten dann auch per Logik selbst auswerten kann.
lg
Stefan
ich möchte noch Deine Fragen beantworten
Ja, das System schickt Alarme und Hinweise an das Nachrichtencenter. Die Infos werden sowohl in der Admin-Web-APP des Timberwolf Servers angezeigt, als auch (automatisch) in der Timberwolf VISU:AndererStefan hat geschrieben: ↑Mo Dez 15, 2025 9:44 pmwelche Sicherheitsvorrichtungen / Warnhinweise gibt es denn derzeit bei volllaufender Festplatte? Zeigt die Visu eine Warnung an?
Hier in diesem Video (in dem es um Seitenwechsel-Sperren geht) sieht man oben rechts das Notification-Icon blinken:
Wenn man dort klickt / touched, dann bekommt man die Nachrichten in der VISU zu sehen:
Hinweis: Zusätzlich kann man aus der Logik auch eigene Nachrichten an das Nachrichtencenter senden (im Bild ist das die obere "Wichtige Nachricht")
Richtig. Wir haben mit Firmware V 4.5 das System-Monitoring eingeführt, damit man auch die Nutzung der Systemressourcen im zeitlichen Verlauf sehen kann.AndererStefan hat geschrieben: ↑Mo Dez 15, 2025 9:44 pmSonst könnte man ja auch einen Alert und eine Notification (via E-Mail, Telegram, ...) in Grafana erstellen.
Letztlich sind das automatisch angelegte Zeitserien, die man mit Klick auf das Grafana Symbol auch dort sehen kann (hier über 30 Tage):
Hinweis: Diese Zeitserien kann man auch in einem Widget auf der VISU anzeigen lassen.
Richtig.AndererStefan hat geschrieben: ↑Mo Dez 15, 2025 9:44 pmIn der "Timberwolf Monitoring DB" findet man unter "sys_stats" den Eintrag "disk_free" (Oder einfach im TWS Interface unter System > Monitor bei Systemüberwachung auf das Grafana-Icon klicken.)
Hinweis: Auf unserer Liste steht, dass wir diese Systemdaten auch als Systemobjekt zur Verfügung stellen, so dass man diese Systemdaten dann auch per Logik selbst auswerten kann.
lg
Stefan
Stefan Werner
Product Owner für Timberwolf Server, 1-Wire und BlitzART
Bitte WIKI lesen. Allg. Support nur im Forum. Bitte keine PN
Zu Preisen, Lizenzen, Garantie, HW-Defekt an service at elabnet dot de
Link zu Impressum und Datenschutzerklärung oben.
Product Owner für Timberwolf Server, 1-Wire und BlitzART
Bitte WIKI lesen. Allg. Support nur im Forum. Bitte keine PN
Zu Preisen, Lizenzen, Garantie, HW-Defekt an service at elabnet dot de
Link zu Impressum und Datenschutzerklärung oben.
-
StefanW
- Elaborated Networks
- Beiträge: 11139
- Registriert: So Aug 12, 2018 9:27 am
- Wohnort: Frauenneuharting
- Hat sich bedankt: 5480 Mal
- Danksagung erhalten: 9563 Mal
- Kontaktdaten:
Lieber Stefan,
lg
Stefan
Ich habe Dir folgendes angeboten:bluegaspode hat geschrieben: ↑Mo Dez 22, 2025 1:45 pmIch fühle mich von der Einordnung in meiner Erstwahrnehmung bestätigt und werde keine weitere Energie zum Server mehr investieren.
Also keinerlei Kostenrisiko für Dich. Nur einsenden bitte. Da auch ein HW-Fehler ursächlich sein könnte, geht das nicht remote.StefanW hat geschrieben: ↑So Dez 21, 2025 8:59 pmSchicke uns das Gerät ein, dann sehen wir uns das an. Wir nehmen die Analyse kostenfrei vor, weil wir wollen das für uns wissen. Liegt der Fehler bei uns, reparieren wir den kostenlos, ansonsten kannst den Server dem Ersatzteillager spenden oder bekommst ihn zurück.
lg
Stefan
Stefan Werner
Product Owner für Timberwolf Server, 1-Wire und BlitzART
Bitte WIKI lesen. Allg. Support nur im Forum. Bitte keine PN
Zu Preisen, Lizenzen, Garantie, HW-Defekt an service at elabnet dot de
Link zu Impressum und Datenschutzerklärung oben.
Product Owner für Timberwolf Server, 1-Wire und BlitzART
Bitte WIKI lesen. Allg. Support nur im Forum. Bitte keine PN
Zu Preisen, Lizenzen, Garantie, HW-Defekt an service at elabnet dot de
Link zu Impressum und Datenschutzerklärung oben.
-
Cepheus73
- Beiträge: 199
- Registriert: Sa Aug 11, 2018 11:36 pm
- Wohnort: München
- Hat sich bedankt: 501 Mal
- Danksagung erhalten: 132 Mal
Das sagt doch eigentlich schon, was das Kernproblem ist: Es geht um ein Gefühl und darauffolgende Festlegung, bei dem Gegenargumente / Angebote etc. gar nicht mehr durchdringen.bluegaspode hat geschrieben: ↑Mo Dez 22, 2025 1:45 pm Ich fühle mich von der Einordnung in meiner Erstwahrnehmung bestätigt.
Ich würde es auch nicht unter wertschätzender Umgang sehen, dass man eine KI einschätzen lässt, ob denn die nicht gewünschte Antwort eine falsche Tonalität enthalten könnte - und das dann auch noch aufs Butterbrot schmieren ...
TW 2600 #178 + TW 3500 #1704 - VPN offen, Zugriff jederzeit
EFH, KNX, 1-Wire, DALI, Wiregate,
CometVisu (TW Docker-Container), Mobotix T25, Logiken für Licht- und Rolladensteuerung
1-Wire-Ventilaktoren + Logiken für Gartenbewässerung
EFH, KNX, 1-Wire, DALI, Wiregate,
CometVisu (TW Docker-Container), Mobotix T25, Logiken für Licht- und Rolladensteuerung
1-Wire-Ventilaktoren + Logiken für Gartenbewässerung
-
bluegaspode
- Beiträge: 84
- Registriert: Sa Nov 09, 2019 10:09 pm
- Hat sich bedankt: 7 Mal
- Danksagung erhalten: 34 Mal
Bitte zeitliche Abfolge im Thread durchaus nochmal betrachten:
1) Problembeschreibung, erste Remote Diagnose mit Hypothesen
2) Ticket aufmachen
-> im Ticket einen aufwändigen Prozess mit einschicken/plattmachen des Servers den ich nicht wollte
3) meine Entscheidung und Publizierung, dass ich das nicht weiter verfolge
(3a) Ablösung des TW in der Hausinstallation, damit Automationen und Visu wieder funktionieren
4) ich muss mich auf 2xA4 Seiten Text beschuldigen lassen, dass ich unfair bin, völlig unvernünftig mit dem Server umgehe, mir sagen lassen, dass mit einem neueren Server mein Problem nicht mehr existiert, dass ich kein Vertrauen habe, dass man eigentlich doch Remote draufschauen könnte ohne Server plattmachen aber weils theoretisch auch ein Hardware Defekt sein könnte, doch lieber Komplettausbau und Postrundweg macht und wenn ich DARAUF nicht anspringe, bekomme ich vorgehalten, dass man ja lieber Probleme löst wenn ich auch dazu bereit wäre.
Für die Transparenz mein Gemütszustand:
Zwischen 1-3 war der normale Grundfrust da, wenn ein System und damit einige Automationen im Haus nicht funktionieren und sich herausstellt, dass es keine schnellen sondern nur aufwändige Lösungen gibt.
Ab 4: auf hundertachtzig,
Wenn die Antwort bei (4) gewesen: "deine Annahmen stimmen nicht, neuere Server haben einen besseren Schutz, leider ist deiner aber älter. Uns ist aufgefallen, dass auch ein schlankerer Prozess noch möglich ist, kostet Y, wie wärs ...", wäre die Sache hier ggf. anders ausgegangen, who knows.
Wenn deine Kritik also ist, dass ich nicht mehr konstruktiv bin, nachdem sich der Protagonist des Forums sich sehr belehrend an mir abgearbeitet hat dann ... hast du vermutlich Recht.
Zuletzt geändert von bluegaspode am Di Dez 23, 2025 4:19 pm, insgesamt 2-mal geändert.
"TWS 350Q ID:417, VPN geschlossen, Reboot nicht erlaubt"